MemOS 2.0
「Stardust」Official Release
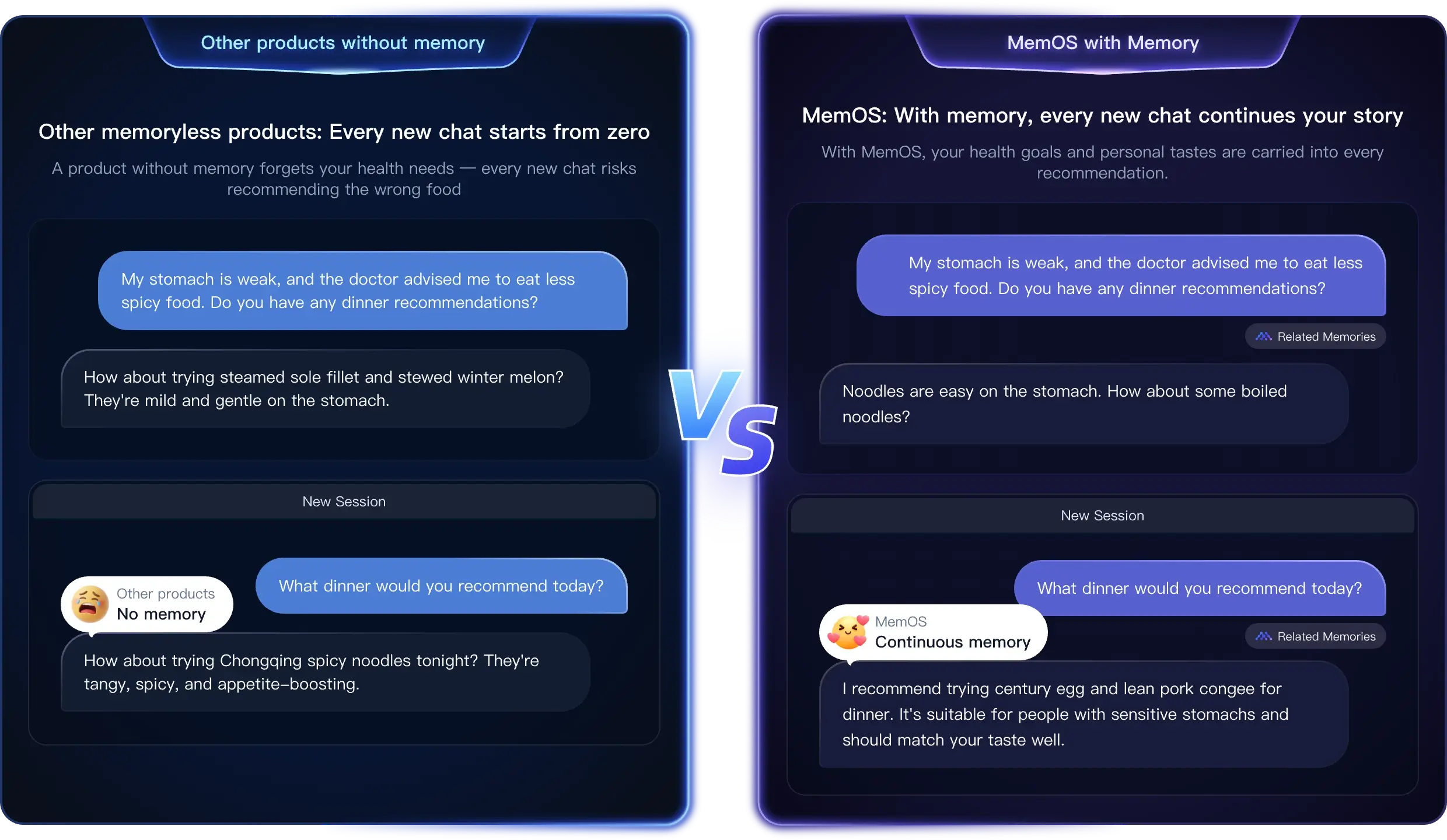
INTELLIGENCE BEGINS WITH MEMORYMemOS Gives AI Continuous Memory & Growth
AI Provides scalable memory for AI, ensuring consistent understanding and personalization across tasks and scenarios

Not only can it remember, but it’s fast
Production-grade memory service with millisecond-level response
MemOS provides businesses with highly available, scalable memory infrastructure
Whether add or search, requests complete in milliseconds
Each call is stable and reliable, and every response is fast and predictable

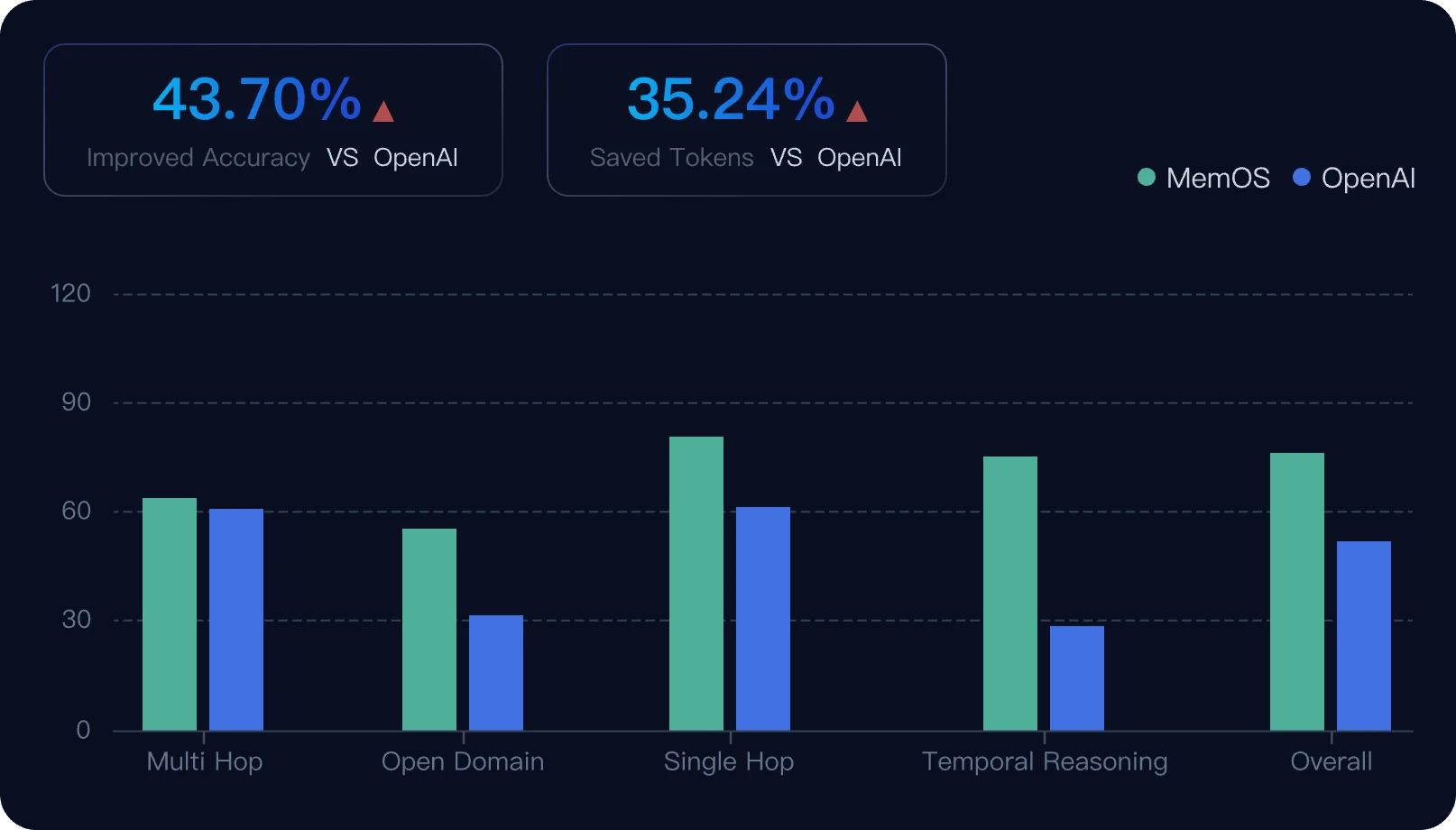
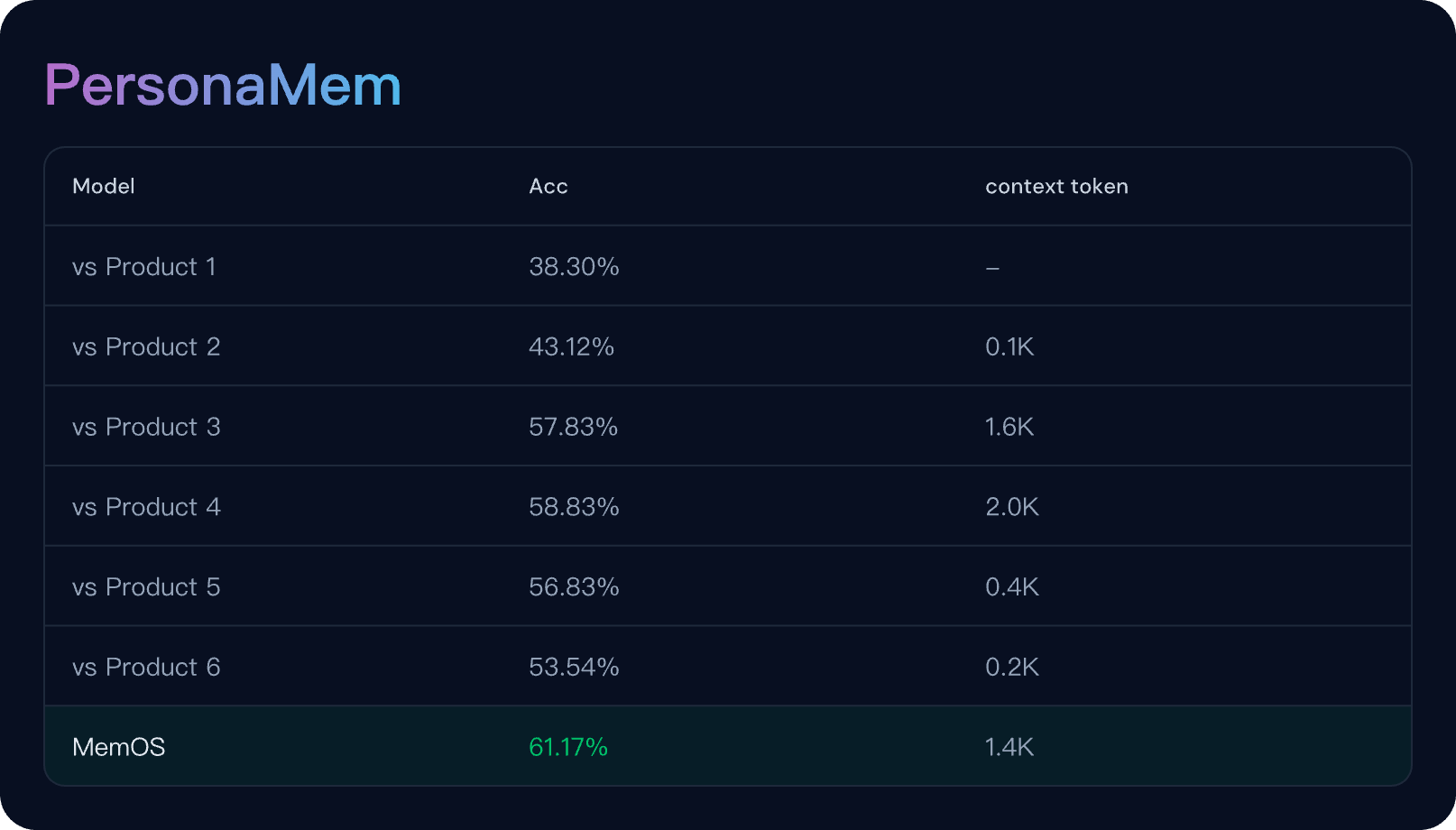
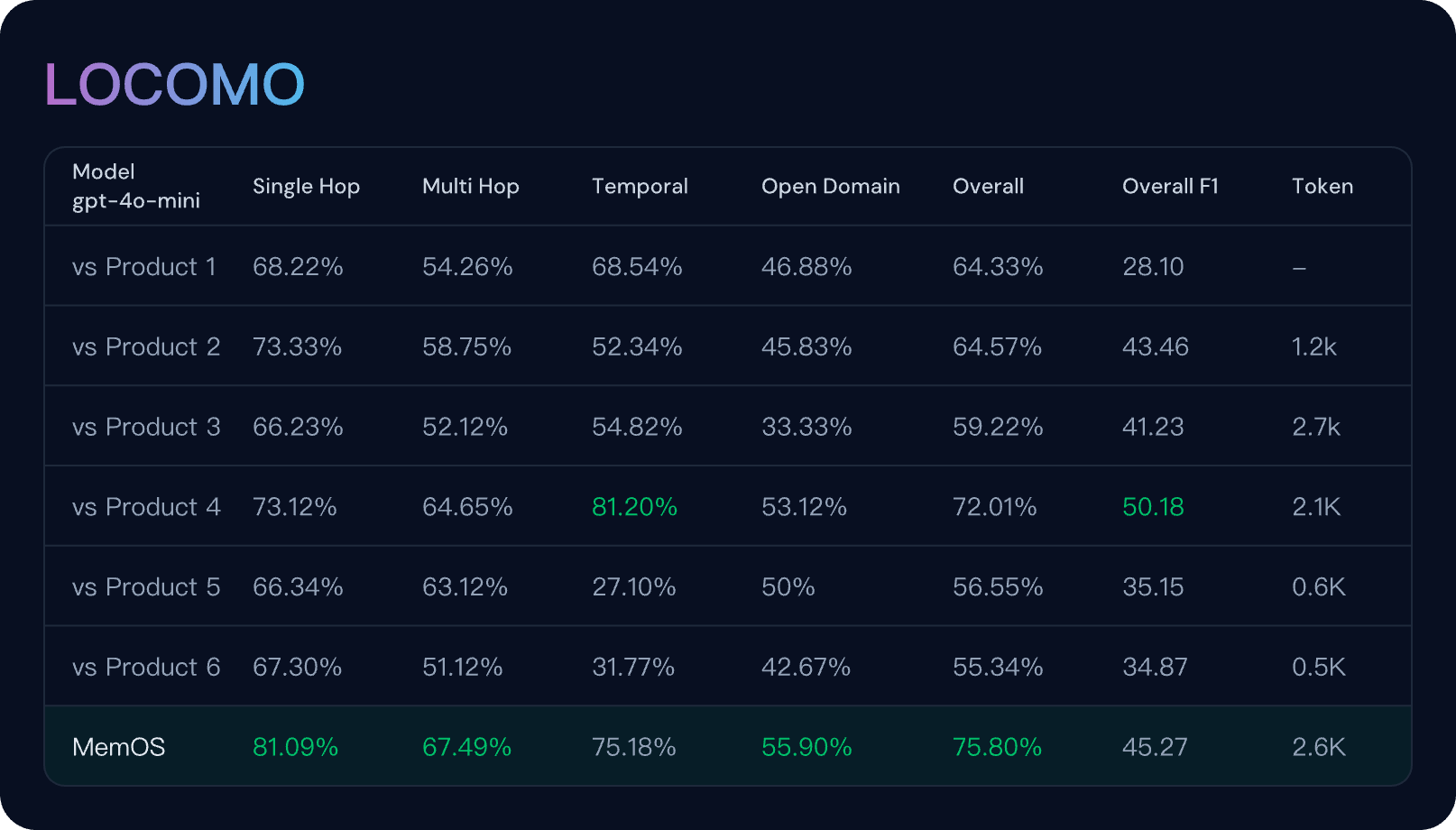
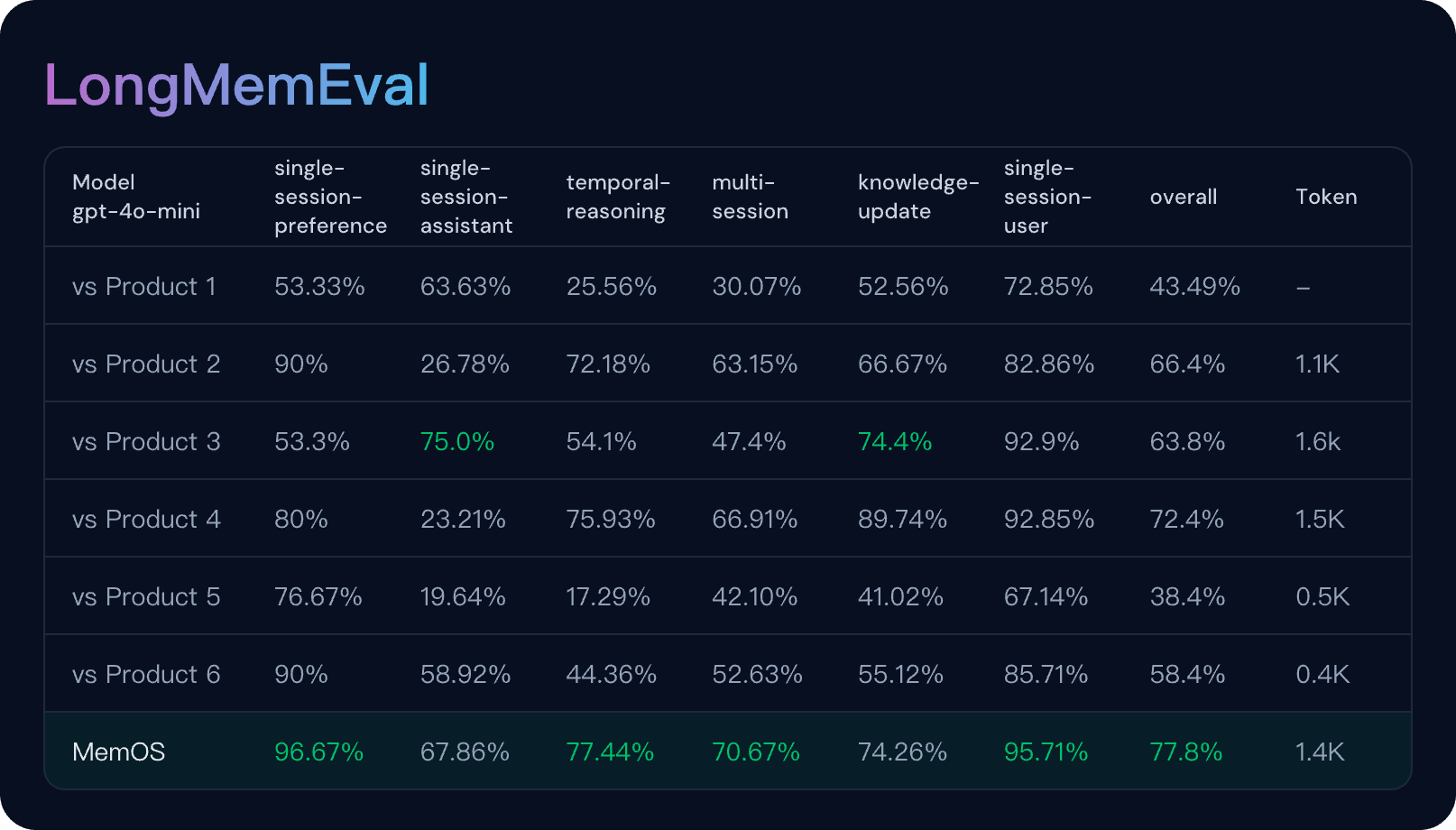
SOTA Performance of MemOS
Evaluated on the LoCoMo Benchmark with LLM-as-a-Judge Metrics, reporting average scores across Temporal Reasoning, Multi-Hop, Open-Domain, and Single-Hop tasks. Comprehensive evaluation details can be found in our accompanying paper
Want the full review? Visit here
Partner Developers & Organizations
Enterprise-grade service · Flexible, secure, and scalable
MemOS provides flexible and stable memory infrastructure for businesses of all sizes and stages
Whether you are in early exploration or large-scale deployment, integration is fast and scaling is seamless
'%3e%3cg%3e%3cpath%20d='M26.6669901875,12L26.6669901875,6.6666667L5.3336586875,6.6666667L5.3336586875,12L26.6669901875,12ZM26.6669901875,14.666667L5.3336586875,14.666667L5.3336586875,25.333334L26.6669901875,25.333334L26.6669901875,14.666667ZM4.0003254875,4L28.0003241875,4C28.7367231875,4,29.3336601875,4.59696007,29.3336601875,5.3333334L29.3336601875,26.666668C29.3336601875,27.403067,28.7367231875,28,28.0003241875,28L4.0003254875,28C3.2639522574999997,28,2.6669921875,27.403067,2.6669921875,26.666668L2.6669921875,5.3333334C2.6669921875,4.59696007,3.2639522574999997,4,4.0003254875,4ZM6.666991987499999,16L10.666991687500001,16L10.666991687500001,22.666668L6.666991987499999,22.666668L6.666991987499999,16ZM6.666991987499999,8L9.3336591875,8L9.3336591875,10.666667L6.666991987499999,10.666667L6.666991987499999,8ZM12.0003261875,8L14.6669911875,8L14.6669911875,10.666667L12.0003261875,10.666667L12.0003261875,8Z'%20fill='%233772FF'%20fill-opacity='1'%20style='mix-blend-mode:passthrough'/%3e%3cpath%20d='M26.6669901875,12L26.6669901875,6.6666667L5.3336586875,6.6666667L5.3336586875,12L26.6669901875,12ZM26.6669901875,14.666667L5.3336586875,14.666667L5.3336586875,25.333334L26.6669901875,25.333334L26.6669901875,14.666667ZM4.0003254875,4L28.0003241875,4C28.7367231875,4,29.3336601875,4.59696007,29.3336601875,5.3333334L29.3336601875,26.666668C29.3336601875,27.403067,28.7367231875,28,28.0003241875,28L4.0003254875,28C3.2639522574999997,28,2.6669921875,27.403067,2.6669921875,26.666668L2.6669921875,5.3333334C2.6669921875,4.59696007,3.2639522574999997,4,4.0003254875,4ZM6.666991987499999,16L10.666991687500001,16L10.666991687500001,22.666668L6.666991987499999,22.666668L6.666991987499999,16ZM6.666991987499999,8L9.3336591875,8L9.3336591875,10.666667L6.666991987499999,10.666667L6.666991987499999,8ZM12.0003261875,8L14.6669911875,8L14.6669911875,10.666667L12.0003261875,10.666667L12.0003261875,8Z'%20fill='url(%23master_svg1_78_51728)'%20fill-opacity='1'%20style='mix-blend-mode:soft-light'/%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Multi-scenario deployment
Supports public cloud, private cloud, on-premises, and hybrid architectures
Meets the needs of teams from startups to large enterprises
Seamlessly connects with existing data and model frameworks, enhancing intelligence without changing existing infrastructure
'%3e%3cg%3e%3cpath%20d='M16.00016309375,1.3333282470703125L28.66683009375,8.666661747070313L28.66683009375,23.333328247070312L16.00016309375,30.666662247070313L3.33349609375,23.333328247070312L3.33349609375,8.666661747070313L16.00016309375,1.3333282470703125ZM7.32533599375,9.436929747070312L17.33363009375,15.231196247070313L17.33363009375,26.813329247070314L26.00016409375,21.795864247070313L26.00016409375,10.204141647070312L16.00016309375,4.414662147070313L7.32533599375,9.436929747070312ZM6.00016279375,11.751048247070312L6.00016279375,21.795864247070313L14.66696409375,26.81346124707031L14.66696409375,16.768661247070312L6.00016279375,11.751048247070312Z'%20fill='%230EB564'%20fill-opacity='1'%20style='mix-blend-mode:passthrough'/%3e%3cpath%20d='M16.00016309375,1.3333282470703125L28.66683009375,8.666661747070313L28.66683009375,23.333328247070312L16.00016309375,30.666662247070313L3.33349609375,23.333328247070312L3.33349609375,8.666661747070313L16.00016309375,1.3333282470703125ZM7.32533599375,9.436929747070312L17.33363009375,15.231196247070313L17.33363009375,26.813329247070314L26.00016409375,21.795864247070313L26.00016409375,10.204141647070312L16.00016309375,4.414662147070313L7.32533599375,9.436929747070312ZM6.00016279375,11.751048247070312L6.00016279375,21.795864247070313L14.66696409375,26.81346124707031L14.66696409375,16.768661247070312L6.00016279375,11.751048247070312Z'%20fill='url(%23master_svg1_78_51788)'%20fill-opacity='1'%20style='mix-blend-mode:soft-light'/%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Efficient & scalable
Model-agnostic and compatible with Agent frameworks, RAG setups, and major model ecosystems
Cloud integration in minutes with just a few lines of code
Maintains millisecond response even at scale for reliable enterprise use
'%3e%3cg%3e%3cpath%20d='M4.11612724375,12L27.88470484375,12C28.62110484375,12,29.21803884375,12.5969601,29.21803884375,13.333334C29.21803884375,13.3702679,29.21643784375,13.4071999,29.21337084375,13.4440002L28.10230284375,26.777334C28.04470484375,27.468399,27.46697084375,28,26.77350384375,28L5.22723384375,28C4.53378034375,28,3.95610034375,27.468399,3.8985136437500003,26.777334L2.78739357045,13.4440002C2.72624682675,12.710227,3.27156707375,12.0657606,4.00539384375,12.0046005C4.04223354375,12.0015335,4.07916724375,12,4.11612724375,12ZM6.45408704375,25.333334L25.54670484375,25.333334L26.43563684375,14.666667L5.56519384375,14.666667L6.45408704375,25.333334ZM17.88603484375,6.6666667L26.66710484375,6.6666667C27.40350384375,6.6666667,28.00043884375,7.2636268,28.00043884375,8L28.00043884375,9.3333335L4.00039374375,9.3333335L4.00039374375,5.3333334C4.00039374375,4.59696007,4.59735384375,4,5.3337276437500005,4L15.21936784375,4L17.88603484375,6.6666667Z'%20fill='%23E031CA'%20fill-opacity='1'%20style='mix-blend-mode:passthrough'/%3e%3cpath%20d='M4.11612724375,12L27.88470484375,12C28.62110484375,12,29.21803884375,12.5969601,29.21803884375,13.333334C29.21803884375,13.3702679,29.21643784375,13.4071999,29.21337084375,13.4440002L28.10230284375,26.777334C28.04470484375,27.468399,27.46697084375,28,26.77350384375,28L5.22723384375,28C4.53378034375,28,3.95610034375,27.468399,3.8985136437500003,26.777334L2.78739357045,13.4440002C2.72624682675,12.710227,3.27156707375,12.0657606,4.00539384375,12.0046005C4.04223354375,12.0015335,4.07916724375,12,4.11612724375,12ZM6.45408704375,25.333334L25.54670484375,25.333334L26.43563684375,14.666667L5.56519384375,14.666667L6.45408704375,25.333334ZM17.88603484375,6.6666667L26.66710484375,6.6666667C27.40350384375,6.6666667,28.00043884375,7.2636268,28.00043884375,8L28.00043884375,9.3333335L4.00039374375,9.3333335L4.00039374375,5.3333334C4.00039374375,4.59696007,4.59735384375,4,5.3337276437500005,4L15.21936784375,4L17.88603484375,6.6666667Z'%20fill='url(%23master_svg1_78_51794)'%20fill-opacity='1'%20style='mix-blend-mode:soft-light'/%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Unified management
Full lifecycle memory control: CRUD, batch cleanup, tagging, and governance
Consistency and low latency ensured under heavy concurrency
Unlock Custom Intelligence with MemOS
A Memory-Native Framework for Building Intelligent Systems that Remember, Adapt, and Evolve
Structured Memory Architecture
MemOS unifies memory types into a layered system, enabling dynamic retrieval, updates, and smarter adaptive learning
Predictive & Asynchronous Scheduling
MemOS employs predictive, intent-aware scheduling to preload relevant memory before it is needed—based on dialogue history, task semantics, or environmental cues.
Predictability & Async Scheduling
MemOS enables memory sharing across models, devices, and apps via MIP, making memory persistent and portable for collaboration and adaptability
MemOS Framework
01Application & API Layer
Provides a unified API for memory operations such as preservation, update, transfer, and rollback—enabling models and agents to integrate structured memory seamlessly into intelligent workflows
Memory Scheduling Layer
Provides a unified API for memory operations such as preservation, update, transfer, and rollback—enabling models and agents to integrate structured memory seamlessly into intelligent workflows.
Storage & Substrate Layer
Serves as the foundation for memory storage and exchange, supporting containerized user, expert, and domain memory—portable across models, sessions, and devices
Memory Scheduling
02Dynamic Knowledge Graph
03
MemOS, suitable for all intelligent application ecosystems
Provides persistent memory for consistent understanding across sessions and tasks.
01.
Long-term Assistants
Remembers user preferences and history for more coherent, context-aware conversations
02.
Multi-scenario Task Coordination
Retains task memory across tools and windows, ensuring consistency in task-switching
03.
Intelligent Agent Collaboration
Supports memory sharing or isolation between agents to improve collaboration and consistency
Start Easy, Build with Less
MemOS brings industrial-grade memory at developer-friendly prices
Free
Great for students, devs, and POCs
$0 /month
Memory API
50K add per month
20K search per month
Chat API
3M input tokens per month
1M output tokens per month
Knowledge Base
Maximum supported: 10
Storage per item: 1G
Community support
Starter
Free Now
Suitable for growing teams
$0 /monthOriginal $19
Memory API
600K add per month
200K search per month
Chat API
12M input tokens per month
4M output tokens per month
Knowledge Base
Maximum supported: 30
Storage per item: 10G
Community support
Pro
Free Now
Made for scaling teams
$0 /monthOriginal $286
Memory API
80M add per month
30M search per month
Chat API
90M input tokens per month
30M output tokens per month
Knowledge Base
Maximum supported: 100
Storage per item: 100G
Dedicated support
Enterprise
Custom enterprise plans
Flexible
Memory API: Unlimited
Chat API: Unlimited
Knowledge Base: Unlimited
Private deployment, own data
Custom integration
Lower latency
Still not enough?
Join the Developer Support Program for Unlimited Chat API Tokens!
Quick Start
Activate MemOS now – just a few lines of code in minutes to add long-term memory to your AI
Join the OpenMem Open Source Community
Dedicated to advancing memory-centered AI systems